What is WarriorGPT and how do I use it?
WarriorGPT is a secure and private generative AI platform for Wayne State students and faculty, designed to mitigate the challenges posed by using intuitional data with external generative AI tools.
- WarriorGPT is available for faculty via Canvas if they choose to enroll their course(s)
- WarriorGPT is available to students registered for current courses in which the assigned instructor has enrolled the course
- WarriorGPT is available to all other employees with AccessID login at warriorgpt.wayne.edu
WarriorGPT is a standalone Generative AI chatbot platform that functions similarly to ChatGPT and other AI chatbots and includes its own guardrails. That means Wayne State can control the quality of the data that users get from the tool and the security of any personal or institutional data that is inputted.
- WarriorGPT does not learn from user input
- WarriorGPT utilizes a large language model pre-trained for ethical engagement
User conversations are not saved in WarriorGPT
How to enroll a Canvas course in WarriorGPT
Follow the instructions below to enroll your course(s) in WarriorGPT. Membership is processed daily.
- Go to canvas.wayne.edu and log in with your AccessID and password.
- Navigate to the course you would like to enroll and open it.
- Click Course Tools in the lefthand menu and then click WarriorGPT Configuration.
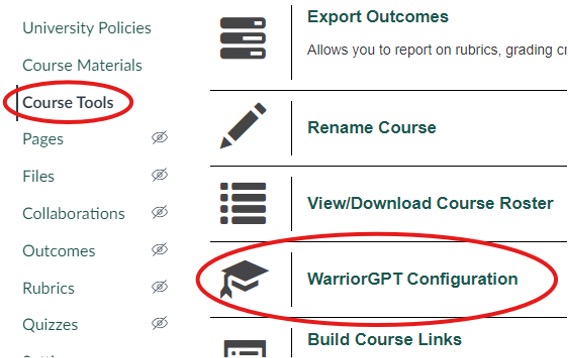
- Check Enable WarriorGPT for your course and then click Submit.

- You should now see WarriorGPT in the lefthand menu. Page refresh may be necessary.
- Repeat this process for all courses you wish to enroll.
WarriorGPT Command Center (temperature, top P, and max token settings)
WarriorGPT is configured with default settings designed to offer the best user experience for all skill levels. Those with advanced knowledge of generative AI can use the Command Center to customize their experience.
To access this menu, accept the user agreement and then click the gear icon in the lower right-hand corner.
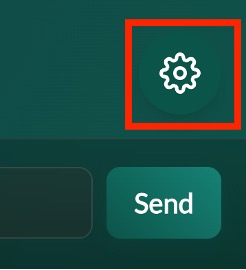
Use this menu to alter the temperature, top P, and max tokens settings.
- Temperature: Like a dial for creativity where 0.1 produces focused and predictable responses; 0.6 (default) produces balanced responses; 2.0 produces highly random and experimental responses; and extreme values (1.5 and over) produce unexpected results.
- Top P: Controls how focused the model is on likely words, where 0.1 uses only the possible words; 0.9 (default) produces a variety; and 1 considers many more possibilities.
- Max tokens: The maximum length of a possible response. Higher values allow for longer responses but may create longer process times.