How to Run a Converge Job
How to Run a Job for Converge on a Single Node
Follow these steps to run a Converge job on a single node.
1. Log on to the Grid.
2. Copy the required contents using the following command:
cp -R /wsu/el7/scripts/tutorial/WSU-Case .
3. Change to the directory that has the job script by typing the following command: cd WSU-Case
4. Edit the job script: vim singlenode_converge.sh
This is contents of the job script:
#!/bin/bash
#SBATCH --job-name Singlenode_Converge
#SBATCH -q secondary
# Request one node
#SBATCH -N 1
# Request 5 MPI processes per node
#SBATCH --ntasks-per-node=5
# Request 5G of memory
#SBATCH --mem=5G
# Request the node features cpu type intel
#SBATCH --constraint=intel
# Send email alert when job begins, ends, requeues
#SBATCH --mail-type=ALL
# Where to send email alerts
#SBATCH --mail-user=xxyyyy@wayne.edu
# Create an error file that will be error_<jobid>.out
#SBATCH -e errors_%j.err
# Set maximum time limit
#SBATCH -t 1-0:0:0
cd ~/WSU-Case/
module load converge/2.4-serial
converge-2.4.16-serial super > output_singlenode_converge.out
NOTE: Be sure to change '#SBATCH --mail-user=xxyyyy@wayne.edu' with YOUR email!
5. To submit the job type: sbatch singlenode_converge.sh
6. The job is submitted. You can check useful job information with the following command: qme
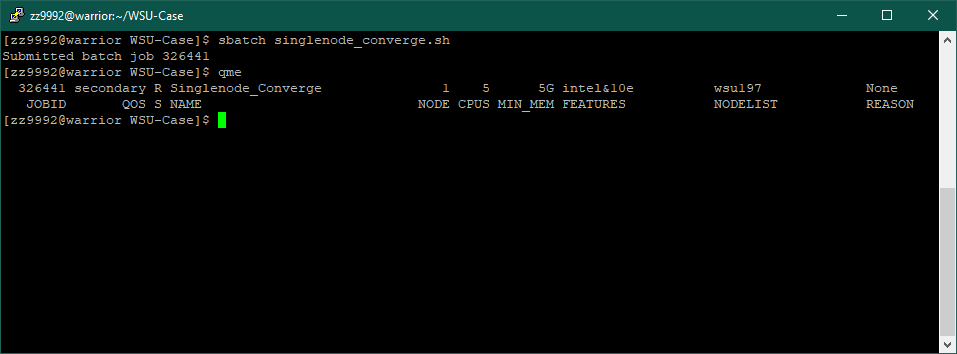
In this example, the job is running on the secondary QoS, the node wsu197, it has 5 CPU's, and the following features: intel cpu type and 10e network. The output can be found in output_singlenode_converge.out.
How to Run a Job for Converge on Multiple Nodes
Follow these steps to run a Converge job on multiple nodes.
1. Log on to the Grid.
2. Copy the required contents using the following command:
cp -R /wsu/el7/scripts/tutorial/WSU_Case .
3. Change to the directory that has the job script by typing the following command: cd WSU-Case
4. Edit the job script: vim multinode_converge.sh
It contains the following:
#!/bin/bash
#SBATCH --job-name Multinode_Converge
#SBATCH -q secondary
# Number of nodes
#SBATCH --nodes=4
# Number of MPI processes per node
#SBATCH --ntasks-per-node=32
# Send email alert when job begins, ends, requeues
#SBATCH --mail-type=ALL
# Where to send email alerts
#SBATCH --mail-user=xxyyyy@wayne.edu
# Create an error file that will be error_<jobid>.out
#SBATCH -e errors_%j.err
# Set maximum time limit
#SBATCH -t 10:00:00
WORKDIR=${HOME}/WSU-Case
if [[ ! -d ${WORKDIR} ]]
then
echo "WORKDIR ${WORKDIR} does not exist" >&2
exit 1
fi
THREADS=`cat $SLURM_JOB_NODELIST | wc -l`
cd ${WORKDIR}
ml swap openmpi3 mpich/3.2.1
ml converge/2.4-mpich
NPROCS=128
srun -n $NPROCS converge-2.4.16-mpich super > output_multinode_converge.out 2>&1
NOTE: Be sure to change '#SBATCH --mail-user=xxyyyy@wayne.edu' with YOUR email!
5. To submit the job, type: sbatch multinode_converge.sh
6. The job is submitted. You can check to see what node it is running on with the following command: qme
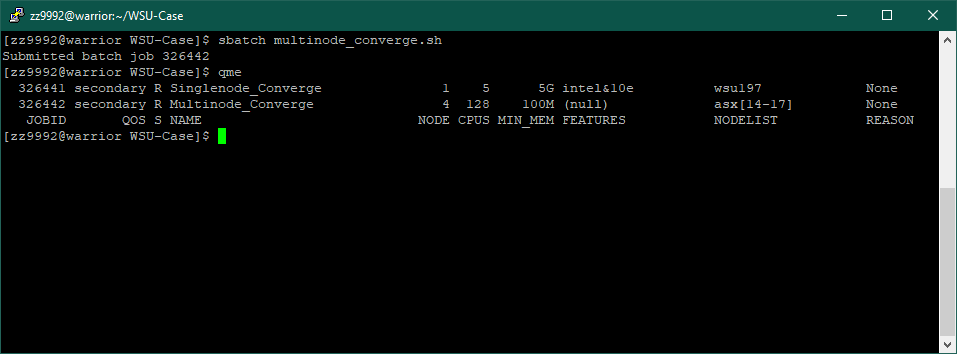
In this example, the job is running on the secondary QoS, on the nodes asx14-17 and with 128 CPU's. The output can be found in the output_multinode_converge.out.